大數(shù)據(jù)列式存儲 Parquet與ORC技術簡介
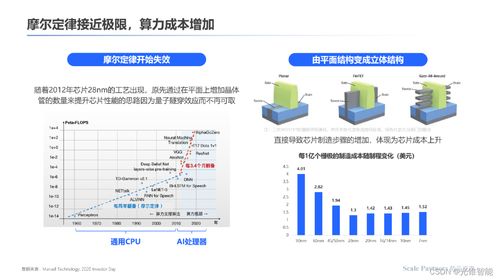
在大數(shù)據(jù)時代,高效的數(shù)據(jù)存儲與查詢是數(shù)據(jù)處理流程中的關鍵環(huán)節(jié)。傳統(tǒng)的行式存儲方式在處理海量數(shù)據(jù)分析任務時,往往面臨I/O效率低、壓縮率差等問題。列式存儲應運而生,通過將同一列的數(shù)據(jù)連續(xù)存儲,顯著提升了分析查詢的性能。本文將重點介紹兩種主流的列式存儲格式:Apache Parquet和Apache ORC,并對它們的特點、適用場景及區(qū)別進行闡述。
一、Apache Parquet
Apache Parquet是一種開源的、面向列的存儲格式,專為Hadoop生態(tài)系統(tǒng)設計。它最初由Twitter和Cloudera合作開發(fā),現(xiàn)已成為Apache頂級項目。Parquet的設計目標是實現(xiàn)高效的數(shù)據(jù)壓縮和編碼,同時支持復雜嵌套數(shù)據(jù)結構。
核心特點:
1. 跨平臺兼容性:Parquet與多種數(shù)據(jù)處理框架兼容,包括Apache Spark、Apache Hive、Apache Impala、Presto等,實現(xiàn)了“一次寫入,多處讀取”的愿景。
2. 高效的壓縮與編碼:Parquet支持多種壓縮算法(如Snappy、Gzip、LZO),并采用自適應編碼技術,根據(jù)列的數(shù)據(jù)類型自動選擇最優(yōu)編碼方式(如字典編碼、游程編碼等),大幅減少存儲空間。
3. 謂詞下推:Parquet允許查詢引擎在讀取數(shù)據(jù)前過濾掉不滿足條件的行,減少不必要的數(shù)據(jù)掃描,提升查詢速度。
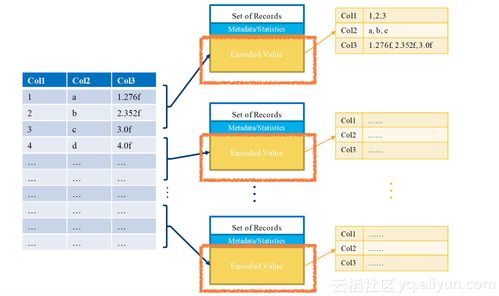
4. 嵌套數(shù)據(jù)支持:通過Dremel風格的記錄拆分與組裝算法,Parquet能夠高效地存儲和處理嵌套結構(如JSON、Protocol Buffers)。
適用場景: Parquet特別適用于讀密集型分析工作負載,尤其是在需要處理復雜嵌套數(shù)據(jù)或跨多個查詢引擎協(xié)作的場景。
二、Apache ORC
Apache ORC(Optimized Row Columnar)是另一種高效的列式存儲格式,專為Hadoop生態(tài)系統(tǒng)優(yōu)化,最初由Hive團隊開發(fā)并用于提升Hive查詢性能。
核心特點:
1. 高性能查詢優(yōu)化:ORC內(nèi)置了輕量級索引,包括每列的最小值、最大值、行計數(shù)等統(tǒng)計信息,并支持布隆過濾器,可快速跳過不相關的數(shù)據(jù)塊。
2. ACID事務支持:ORC格式原生支持ACID事務,適用于需要數(shù)據(jù)一致性保障的場景,如實時數(shù)據(jù)更新、刪除操作。
3. 高效的壓縮:ORC使用類型感知的壓縮(如Integer使用游程編碼,String使用字典編碼),并支持Zlib、Snappy等壓縮算法,壓縮率通常優(yōu)于Parquet。
4. 預測下推與向量化處理:ORC允許復雜謂詞下推,并與Hive的向量化查詢引擎深度集成,進一步加速查詢執(zhí)行。
適用場景: ORC非常適合Hive為中心的生態(tài)系統(tǒng),尤其是在需要ACID事務支持、頻繁進行數(shù)據(jù)更新或?qū)Σ樵冃阅苡袠O高要求的場景。
三、Parquet與ORC對比
雖然Parquet和ORC都是優(yōu)秀的列式存儲格式,但它們在設計哲學和優(yōu)化重點上有所不同:
- 生態(tài)系統(tǒng):Parquet更注重跨平臺兼容性,與Spark、Impala等集成更廣泛;ORC則與Hive生態(tài)綁定更緊密,對Hive的支持更為深入。
- 事務支持:ORC原生支持ACID事務,而Parquet本身不直接支持,需借助Delta Lake、Apache Iceberg等外部表格式實現(xiàn)。
- 嵌套數(shù)據(jù):Parquet對復雜嵌套結構的處理更為成熟和靈活;ORC雖然也支持,但相對簡化。
- 壓縮與性能:ORC通常提供更高的壓縮率和更快的查詢速度(尤其在Hive中),而Parquet在跨引擎兼容性和嵌套數(shù)據(jù)處理上更具優(yōu)勢。
四、數(shù)據(jù)處理與存儲支持服務
在實際的大數(shù)據(jù)平臺中,選擇Parquet或ORC需綜合考慮業(yè)務需求、技術棧和性能目標。數(shù)據(jù)處理和存儲支持服務通常包括:
- 格式選擇咨詢:根據(jù)數(shù)據(jù)特性(如結構復雜度、更新頻率)和查詢模式,推薦合適的存儲格式。
- 性能調(diào)優(yōu):通過調(diào)整壓縮算法、塊大小、索引設置等參數(shù),優(yōu)化存儲效率與查詢速度。
- 遷移與轉(zhuǎn)換服務:協(xié)助將現(xiàn)有數(shù)據(jù)從其他格式(如CSV、Avro)轉(zhuǎn)換為Parquet或ORC,并確保數(shù)據(jù)一致性。
- 監(jiān)控與維護:提供存儲健康狀態(tài)監(jiān)控、數(shù)據(jù)壓縮率分析和生命周期管理服務。
###
Parquet和ORC作為大數(shù)據(jù)領域主流的列式存儲格式,各有千秋。Parquet以其出色的跨平臺兼容性和嵌套數(shù)據(jù)支持,成為多引擎環(huán)境下的首選;ORC則憑借其在Hive生態(tài)中的深度優(yōu)化和ACID事務支持,在特定場景下表現(xiàn)卓越。在實際應用中,團隊應結合自身技術棧和業(yè)務需求,做出明智選擇,并輔以專業(yè)的數(shù)據(jù)處理與存儲支持服務,以充分釋放大數(shù)據(jù)分析的潛力。
---
本文由Coco根據(jù)1998年2月的專欄及CSDN博客相關內(nèi)容整理,旨在為大數(shù)據(jù)從業(yè)者提供Parquet與ORC格式的技術簡介與選型參考。
如若轉(zhuǎn)載,請注明出處:http://www.nnxinfangxiang.cn/product/49.html
更新時間:2026-03-01 12:14:32